flowchart LR
A["Side A\n(e.g., riders, cardholders, users)"]
P["PLATFORM\nsets price structure\n(p_A, p_B)"]
B["Side B\n(e.g., drivers, merchants, advertisers)"]
A -- "cross-side effect (+)" --> B
B -- "cross-side effect (+)" --> A
P -. "p_A (often subsidized)" .-> A
P -. "p_B (money side)" .-> B
66 Platforms and Two-Sided Markets
A platform is an intermediary that creates value primarily by enabling direct interactions between two or more distinct groups of users. The defining feature is not that the firm sells a product but that it sells access: a credit-card network sells merchants access to cardholders and cardholders access to merchants; a ride-hailing app sells riders access to drivers and drivers access to riders; a videogame console sells gamers access to titles and developers access to an installed base. What makes platforms a distinct object of study—rather than ordinary resellers who buy and resell—is that the value each side derives depends on how many and which users join the other side. Demand is interdependent across groups, and that interdependence rewrites the firm’s pricing, product, and competitive problems.
This chapter treats the platform as two tightly coupled objects: an economic structure (a market with cross-group externalities that the platform internalizes through prices and governance) and a strategic asset (an installed base whose growth is self-reinforcing and whose tipping dynamics can hand a market to a single winner). A serious account must connect the two, because the central managerial decisions—what to charge each side, whom to subsidize, how to solve the chicken-and-egg launch problem, how to govern the interactions that occur on the platform—follow directly from the externality structure. The economics is due in large part to the two-sided-market theory of Rochet and Tirole, and to the platform-pricing analyses of Parker–Van Alstyne and of Armstrong, who worked out the structure logic; the strategic machinery traces to the network-effects literature begun by Katz and Shapiro (1985) and its companion analyses of standards and compatibility.
The chapter proceeds from the inside out. It begins with the raw force that distinguishes platforms—network effects and their cross-side cousins—and defines them formally. It then builds the pricing structure problem, derives the canonical Rochet–Tirole condition, and confronts what the structure implies for which side pays and which is subsidized. From there it treats the dynamic problems managers actually face: the chicken-and-egg launch problem, tipping and multihoming, governance of the interactions a platform hosts, and competition among platforms. It closes with measurement—how an analyst estimates network effects from data, what identification assumptions that requires, and what breaks them—and supplies reproducible code.
66.1 Network Effects and Cross-Side Externalities
The primitive is the network effect (or network externality): a good exhibits a network effect when a user’s utility from it increases in the number of other users. The telephone is the textbook case—a phone is useless if no one else owns one, and its value rises with every additional subscriber. Formally, let \(u_i\) denote user \(i\)’s utility and \(n\) the number of adopters. A pure (within-side, or same-side) network effect holds when \(\partial u_i / \partial n > 0\). The effect is direct when utility depends on the raw count of fellow users and indirect when it operates through a complementary product whose supply rises with the user base (more console owners induce more game titles, which in turn attract more console owners).
Platforms add a second, asymmetric channel. Let the two sides be \(A\) and \(B\) with participation \(n_A\) and \(n_B\). A cross-side network effect, or cross-group externality, holds when a user on side \(A\) benefits from participation on side \(B\):
\[ \frac{\partial u_A}{\partial n_B} > 0, \tag{66.1}\]
and symmetrically for side \(B\). Cross-side effects are the engine of the two-sided market: merchants value more cardholders, cardholders value more accepting merchants, and the platform sits between them internalizing both. Crucially, cross-side effects need not be symmetric in sign or magnitude. In media markets the effect can be negative in one direction—viewers dislike advertisers even as advertisers value viewers—so a television network or a search engine maximizes by restraining the ad side to protect the audience side. Within-side effects can likewise be negative: more merchants on a marketplace intensifies competition among them, and more drivers on a ride app thins each driver’s earnings.
A landmark statement frames the construct:
A market is two-sided if the platform can affect the volume of transactions by charging more to one side of the market and reducing the price paid by the other side by an equal amount; in other words, the price structure matters, and platforms must design it so as to bring both sides on board.
— after Rochet and Tirole’s characterization of two-sided markets
The italicized claim—that the structure of prices, not merely their level, affects volume—is what separates a two-sided market from an ordinary one and is the source of nearly everything distinctive in platform strategy. We make it precise below.
It is worth distinguishing two phenomena that are often conflated. A network effect is a property of demand: it concerns how users’ valuations move with participation. A scale economy is a property of cost: it concerns how average cost moves with output. The two generate superficially similar “bigger is better” dynamics, but they are not the same and have different policy and competitive implications—a platform can enjoy strong demand-side network effects while running at roughly constant marginal cost, and a manufacturer can enjoy steep scale economies with no network effect at all. Conflating them leads analysts to attribute to network effects market structure that is really driven by fixed costs, and vice versa.1
66.2 Pricing Structure
The defining managerial decision in a two-sided market is not the level of price but its structure—how the total price is allocated across the two sides. Because a user on side \(A\) confers a benefit on side \(B\) (and conversely), the platform can profitably charge one side below its own marginal cost, even below zero, recouping the subsidy from the side that values access more. This is why so many platforms give one side away free: free consumer search funded by advertisers, free operating systems funded by application developers, free ride-app signup funded by per-trip commissions.
66.2.1 The Rochet–Tirole Condition
Consider a monopoly platform facing sides \(A\) and \(B\). Let \(p_A\) and \(p_B\) be the per-interaction prices, and suppose the volume of interactions \(V\) depends on the participation each price induces on each side, \(V = D_A(p_A)\,D_B(p_B)\) in a reduced form, with constant marginal cost \(c\) per interaction. The platform chooses \((p_A, p_B)\) to maximize profit
\[ \pi = (p_A + p_B - c)\,V(p_A, p_B). \tag{66.2}\]
The first-order conditions deliver a generalization of the Lerner rule in which the markup charged to each side is governed by that side’s demand elasticity. Writing \(\eta_A\) and \(\eta_B\) for the (own-price) elasticities of participation, the optimal structure satisfies
\[ \frac{p_A + p_B - c}{p_A} = \frac{1}{\eta_A}, \qquad \frac{p_A + p_B - c}{p_B} = \frac{1}{\eta_B}, \tag{66.3}\]
so that the ratio of prices across sides is inversely related to the ratio of elasticities. The intuition is sharp and is the central takeaway of the entire pricing literature: the side that is more elastic—more reluctant to join, more price-sensitive, more easily lost to an outside option—pays less, and the side that values the interaction more inelastically pays more. The platform allocates the burden to the side that will tolerate it, because every user retained on the elastic side is worth more through the cross-side externality than the revenue forgone from subsidizing them.
Two forces refine this. First, the strength of the cross-side externality each side exerts pulls price the other way: a side that confers a large benefit on the other side should be subsidized to bring it on board, independent of its own elasticity. A platform thus subsidizes the side that is either very price-sensitive or very valuable to the opposite side—often the same side (consumers are both fickle and the reason advertisers pay). Second, whether users single-home (join one platform) or multihome (join several) reshapes the markup: when one side multihomes and the other single-homes, the platform holds a competitive bottleneck over access to the single-homing side and extracts rents from the multihoming side, a result we return to under platform competition.
66.2.2 What the Structure Implies
Three implications of Equation 66.3 organize how managers read platform pricing.
The first is below-cost and negative pricing as an equilibrium, not a promotion. When one side is highly elastic and confers a strong externality, the profit-maximizing \(p_A\) can be negative—the platform pays users to join (sign-up bonuses, free hardware sold below cost, cashback). This is not predatory pricing in the antitrust sense and not a temporary loss leader; it is the structure the externalities call for, and it persists in steady state. Misreading a subsidized side as evidence of below-cost predation is a recurring error in both managerial and regulatory analysis of platforms.
The second is that the identity of the subsidized side is an empirical question, not a convention. It depends on relative elasticities and externality strengths, both of which vary by market and over the life cycle. Newspapers historically subsidized readers and charged advertisers; some digital outlets have inverted this with reader paywalls as ad demand softened. The structure is not fixed by industry; it is chosen, and re-chosen as conditions move.
The third concerns price floors and the limits of the logic. The subsidy to one side is bounded by the threat that subsidized “users” are not genuine participants but arbitrageurs who consume the subsidy without conferring the externality—fake accounts harvesting sign-up bonuses, drivers who never complete trips. The platform’s ability to run an aggressive price structure is therefore inseparable from its ability to govern who is on the platform, which we take up in Section 66.5.
Table 66.1 summarizes how the structure resolves across canonical platforms.
| Platform type | Subsidized side | Money side | Why (elasticity / externality) |
|---|---|---|---|
| Payment card network | Cardholders (rewards) | Merchants (fees) | Cardholders elastic and confer large externality on merchants |
| Search engine / ad-funded media | Users (free) | Advertisers (auctions) | Users elastic; advertisers value access inelastically |
| Console videogames | Gamers (hardware sold near cost) | Developers (royalties) | Installed base drives developer willingness to pay |
| Ride-hailing | Riders (low fares early) | Drivers, then riders (commission) | Both sides elastic at launch; structure shifts with maturity |
| B2B marketplace | Buyers (free to browse) | Sellers (listing/transaction fees) | Sellers value buyer access; buyers easily lost |
Figure 66.1 gives the general anatomy: two sides linked by cross-side network effects, with the platform choosing how to split the total price across them.
66.3 The Chicken-and-Egg Problem
Cross-side externalities that drive a mature platform’s profits are a curse at launch. No user on side \(A\) wants to join until side \(B\) is present, and no user on side \(B\) wants to join until side \(A\) is present: each side’s participation is a best response to the other’s, and the empty market—where neither side joins—is always an equilibrium. This is the chicken-and-egg problem (also the penguin problem, after penguins who will not be first into the water), and it is the central obstacle to platform entry.
Formally, write expected utility for a representative side-\(A\) user as \(u_A(n_B^e)\), increasing in the expected side-\(B\) participation \(n_B^e\), and symmetrically for side \(B\). An adoption equilibrium is a fixed point \((n_A^*, n_B^*)\) at which each side’s participation is consistent with the other’s. Because the best-response curves both slope upward, the system generically admits multiple equilibria, including the no-adoption point \((0,0)\). Coordinating users away from the empty equilibrium toward a high-participation one is the launch problem; expectations are self-fulfilling, so the platform must manufacture the belief that the other side will show up.
The strategies platforms use to escape the bad equilibrium map cleanly onto this structure:
- Subsidize one side hard at launch, even at a loss, to seed participation that makes joining a best response for the other side. This is the dynamic counterpart to the static pricing structure: early subsidies are an investment in expectations.
- Solve one side’s problem in a single-sided mode first, then open the second side—the “come for the tool, stay for the network” pattern. A product that is standalone-useful to side \(A\) bootstraps an installed base before any side-\(B\) participation is required, breaking the simultaneity.
- Micromarket / zip-code launch: ignite the network in one narrow geography or vertical where the critical mass needed for a viable interaction is small, then replicate. Density, not aggregate scale, is what makes a local marketplace tip, so a platform that achieves liquidity in one city before expanding faces a far smaller coordination problem than one launching everywhere thinly.
- Seed the marquee side: recruit a small number of high-value side-\(B\) participants (anchor merchants, marquee game titles, celebrity sellers) whose presence credibly signals that the other side will follow.
The unifying logic is that all four reduce the expected participation gap that any joining user must bridge—either by directly buying participation, by removing the cross-side dependence at launch, or by shrinking the critical mass needed for the first viable interactions.
66.4 Tipping, Critical Mass, and Multihoming
Network effects make platform markets prone to tipping: once one platform’s installed base pulls ahead, the cross-side externalities make it ever more attractive, the lead widens, and the market collapses toward a single dominant platform or a narrow oligopoly. The qualitative dynamic is a positive-feedback loop, and the quantitative threshold above which it ignites is the platform’s critical mass—the participation level beyond which growth becomes self-sustaining without further subsidy.
A minimal model makes the threshold visible. Suppose the fraction of a market that adopts in the next period, \(x_{t+1}\), responds to current adoption \(x_t\) through an S-shaped (logistic) best-response map driven by network value,
\[ x_{t+1} = \frac{1}{1 + e^{-\beta\,(x_t - \theta)}}, \tag{66.4}\]
where \(\beta\) scales the strength of the network effect and \(\theta\) is an adoption cost or threshold parameter. The map has up to three fixed points: a low (often zero) equilibrium, an unstable interior fixed point that is exactly the critical mass, and a high equilibrium near full adoption. Starting below critical mass, the system decays to the empty market; starting above it, the system tips to dominance. The managerial content of the chicken-and-egg subsidy is precisely to push initial adoption past the unstable interior point.
Whether a market actually tips, however, depends on three moderators that practitioners frequently overlook:
Multihoming. If users cheaply join several platforms at once, no single platform monopolizes access to them, the winner-take-all force weakens, and the market sustains multiple platforms in equilibrium. Tipping requires that at least one side predominantly single-homes. Drivers and riders who run several apps simultaneously are the reason ride-hailing has not tipped to a single platform in most cities, despite strong cross-side effects.
Differentiation and heterogeneous needs. When users have heterogeneous tastes and platforms differentiate, distinct platforms can serve distinct segments and coexist—niche professional networks alongside a general one—because the network benefit of the dominant platform does not dominate the fit benefit of the specialized one for every user.
Capacity and congestion (negative same-side effects). When more participation degrades the experience—congestion, thinner matches, intra-side competition—the positive feedback is damped and full tipping is resisted.
The practical upshot is that “network effects imply winner-take-all” is a half-truth. Network effects create a tendency to tip; multihoming, differentiation, and congestion determine whether the tendency is realized. An analyst who observes a fragmented platform market should look first to these moderators rather than conclude the network effects are weak.
66.5 Platform Governance
Because a platform’s value is the interactions it hosts rather than a product it makes, the platform’s central operational task is governance: the rules, prices, information, and enforcement that determine who may participate, what interactions are permitted, and how disputes and quality are managed. Governance is to a platform what manufacturing is to a product firm—the locus where value is actually produced or destroyed—and it is the lever that makes an aggressive price structure (Chapter 66) sustainable by ensuring subsidized participants are genuine.
Three governance problems recur.
Quality and adverse selection. Open access invites low-quality participants whose presence imposes a negative cross-side externality (counterfeit sellers, bad drivers, spam advertisers). The platform’s classic remedy is a reputation system—ratings and reviews that aggregate private experience into a public signal, mitigating the lemons problem that would otherwise unravel the market (Akerlof 1970). Reputation systems are themselves a designed object: how reviews are solicited, displayed, and responded to changes the information they convey. Hotels that begin responding to reviews gain in average rating but receive fewer, longer negative reviews thereafter, as dissatisfied users self-censor unjustified complaints under anticipated scrutiny (Proserpio and Zervas 2017)—a reminder that governance interventions change participant behavior, not merely measure it.
The platform’s own role as competitor. A platform that both hosts third-party sellers and sells its own products faces a conflict: data on third-party demand can be used to enter their niches, and ranking algorithms can be tilted toward house products. This self-preferencing problem trades short-run platform profit against long-run participation incentives, because sellers who fear expropriation invest less or exit.
Openness versus control. A platform chooses how open to be—how freely third parties may build on it, transact, and access its users. More openness recruits more complementors and accelerates indirect network effects; more control protects quality, captures more value, and guards the core experience. The choice is not binary but a governance gradient, and the optimal point shifts over the life cycle: openness to bootstrap the network early, selective control to monetize and protect quality once the network is established.
66.6 Platform Competition
When platforms compete, the network-effects logic interacts with the pricing-structure logic to produce dynamics with no single-sided analogue. Three results organize the field.
Competitive bottlenecks. When one side single-homes and the other multihomes, each platform is a monopoly gatekeeper over its single-homing users, because reaching them requires joining that platform. Competing platforms then compete fiercely for the single-homing side (often subsidizing it heavily) and extract rents from the multihoming side, which has no choice but to join all platforms to reach all of the single-homing users. This explains why advertisers (who multihome across media) pay, while audiences (who often single-home their attention) are courted.
Envelopment. A platform in an adjacent market can attack an incumbent by bundling an overlapping functionality into its own user base, leveraging shared users to enter without solving the chicken-and-egg problem from scratch. Platform competition is therefore frequently cross-market rather than within a narrowly defined product market—a messaging app entering payments, a search engine entering maps—and an incumbent’s most dangerous rival is often a large platform from a neighboring market rather than a direct entrant.
Compatibility and standards. Competing platforms choose whether to be compatible—to let their networks interconnect (as banks share an ATM network) or remain proprietary. Compatibility converts a fragmented set of small networks into one large network, eliminating the network-effect basis for competition and shifting rivalry to price and features; incompatibility preserves the prize of tipping but risks splitting the market. The strategic choice of compatibility is thus a choice about whether to compete on network size at all, and the firm with the larger installed base typically prefers incompatibility (to press its advantage) while the smaller prefers compatibility (to neutralize it)—the classic asymmetry of standards wars (Katz and Shapiro 1985).
66.7 Measuring Network Effects
For both research and managerial decisions the quantity of interest is the magnitude of the network effect: by how much does a user’s adoption or value rise with the size of the relevant network? The estimation problem is hard because the very feedback that defines a network effect also confounds its measurement.
66.7.1 The Reflection / Simultaneity Problem
Let adoption (or value) for a user \(i\) on side \(A\) depend on the participation of side \(B\),
\[ y_{iA} = \alpha + \gamma\, n_B + \mathbf{x}_{iA}'\boldsymbol{\beta} + \varepsilon_{iA}, \tag{66.5}\]
where \(\gamma\) is the cross-side network-effect coefficient we wish to recover. The naive regression of \(y_{iA}\) on \(n_B\) is biased for three reasons, each fatal on its own.
First, simultaneity: \(n_B\) is itself determined by \(n_A\) (which aggregates the \(y_{iA}\)), so \(n_B\) is correlated with \(\varepsilon_{iA}\) through the very feedback loop Equation 66.1 describes. This is the platform analogue of the reflection problem in the study of social interactions—each side’s behavior reflects the other’s, and the two cannot be disentangled without an exclusion restriction.
Second, correlated unobservables: a city that is attractive to riders (good weather, dense nightlife) is also attractive to drivers, so \(n_B\) and \(\varepsilon_{iA}\) share common demand shifters that masquerade as a network effect.
Third, homophily / sorting: users who join a popular platform may differ in unobserved ways from those who do not, biasing the cross-sectional association.
66.7.2 Identification Strategies
Credible estimates therefore lean on one of a few designs, each buying identification with an explicit and falsifiable assumption.
Instrumental variables. Find a variable that shifts side-\(B\) participation \(n_B\) but is excluded from side \(A\)’s utility Equation 66.5 given controls—a cost shock or policy change affecting only side \(B\). The estimator is two-stage least squares; the identifying assumption is the exclusion restriction, which is not testable and must be argued substantively. Weak instruments (a first stage that barely moves \(n_B\)) deliver badly biased second-stage estimates, so the first-stage \(F\)-statistic must be reported and large.
Structural estimation of demand with network effects. Specify utility with a network term and estimate the system jointly, instrumenting for the endogenous installed base within a discrete-choice demand model in the tradition of Berry, Levinsohn, and Pakes (1995). The payoff is a fully specified model that supports counterfactuals (what if the platform changed its price structure?); the cost is that identification now rests on the full set of functional-form and distributional assumptions, and misspecification of the network term contaminates every counterfactual.
Natural experiments and panel variation. A discrete shock that adds or removes participation on one side—an entry, an exit, a regulatory ban, a platform policy change rolled out in some markets and not others—permits a difference-in-differences estimate of the cross-side effect, with the parallel-trends assumption replacing the exclusion restriction as the identifying premise.
66.7.3 A Reproducible Illustration
The simulation below makes the simultaneity bias concrete. We generate a two-sided market in which participation on each side genuinely responds to the other (a true cross-side effect), plus a market-level demand shifter that raises participation on both sides. We then show that the naive OLS regression of side-\(A\) participation on side-\(B\) participation overstates the network effect, while an instrument that shifts only side \(B\) recovers the truth.
Code
set.seed(20260620)
n_markets <- 500
gamma_true <- 0.40 # true cross-side effect of n_B on n_A
# Market-level demand shifter raising BOTH sides (the confound)
demand_shock <- rnorm(n_markets)
# Side-B cost instrument: shifts n_B only (excluded from side-A utility)
z_B <- rnorm(n_markets)
# Side-B participation: driven by the instrument and the common demand shock
n_B <- 0.9 * z_B + 0.8 * demand_shock + rnorm(n_markets)
# Side-A participation: true response to n_B, plus the same demand shock
eps_A <- 0.8 * demand_shock + rnorm(n_markets) # correlated unobservable
n_A <- gamma_true * n_B + eps_A
dat <- data.frame(n_A, n_B, z_B)
# (1) Naive OLS: biased upward by the shared demand shock
ols <- lm(n_A ~ n_B, data = dat)
# (2) 2SLS by hand: instrument n_B with z_B
first <- lm(n_B ~ z_B, data = dat)
n_B_hat <- fitted(first)
iv <- lm(n_A ~ n_B_hat, data = dat)
cat("True cross-side effect (gamma):", gamma_true, "\n")
#> True cross-side effect (gamma): 0.4
cat("Naive OLS estimate: ", round(coef(ols)["n_B"], 3), "\n")
#> Naive OLS estimate: 0.656
cat("2SLS (IV) estimate: ", round(coef(iv)["n_B_hat"], 3), "\n")
#> 2SLS (IV) estimate: 0.403
cat("First-stage F-statistic: ",
round(summary(first)$fstatistic["value"], 1), "\n")
#> First-stage F-statistic: 237.1The OLS coefficient is inflated well above \(\gamma = 0.40\) because the shared demand shock loads onto both sides; the instrumented estimate recovers the true effect, and the first-stage \(F\) confirms the instrument is strong. The lesson generalizes: any estimate of a network effect that does not confront the simultaneity of the two sides should be read as an upper bound, not an effect.
The next chunk visualizes the tipping dynamics of Equation 66.4, showing the unstable interior fixed point that is the platform’s critical mass.
Code
beta <- 12 # strength of the network effect
theta <- 0.5 # adoption threshold
f <- function(x) 1 / (1 + exp(-beta * (x - theta)))
x <- seq(0, 1, length.out = 400)
plot(x, f(x), type = "l", lwd = 2,
xlab = "Current adoption x_t",
ylab = "Next-period adoption x_(t+1)",
main = "Network tipping and critical mass")
abline(0, 1, lty = 2) # 45-degree line: fixed points are crossings
# Locate the unstable interior fixed point (critical mass) near x = theta
g <- function(x) f(x) - x
crit <- uniroot(g, c(0.3, 0.7))$root
points(crit, crit, pch = 19)
text(crit, crit, " critical mass", pos = 4)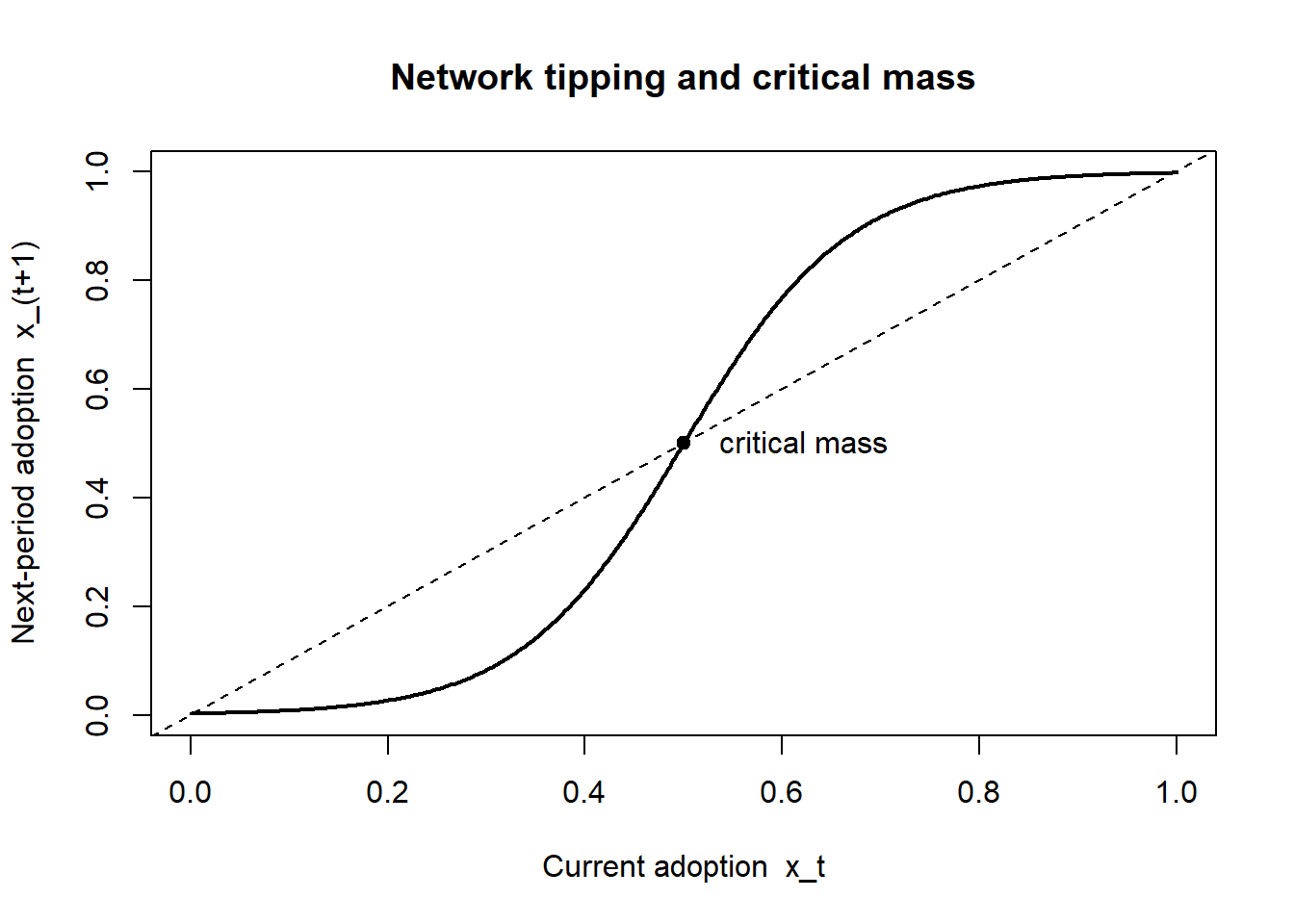
66.8 Marketplace and Digital-Platform Applications
The framework applies across a wide span of commercially important platforms, and the same constructs—cross-side externalities, price structure, chicken-and-egg, tipping, multihoming, governance—resolve differently as their parameters differ.
Marketplaces (horizontal commerce platforms matching buyers and sellers) live or die on liquidity—the probability that a given listing finds a counterparty quickly. Liquidity is a same-market density requirement, which is why marketplaces launch narrow (one category, one city) and why the chicken-and-egg subsidy is usually aimed at the supply side, whose presence is the binding constraint on the first viable transactions. Governance—reputation, dispute resolution, fraud control—is the operating core, because a single bad interaction imposes a negative cross-side externality on the whole market.
Ad-funded digital media (search, social, video) are the canonical case of an asymmetric, partly negative cross-side effect: users dislike ads even as advertisers value users. The price structure gives the user side away free and monetizes the advertiser side, typically through auctions that price advertiser access to attention, and the central governance tension is how much advertising load to impose before the negative externality erodes the audience the advertisers are paying for.
Transaction platforms with strong multihoming (ride-hailing, food delivery) illustrate the limits of tipping: because both sides cheaply run multiple apps, these markets sustain competition despite powerful cross-side effects, and the strategic contest is over inducing single-homing (loyalty programs, exclusivity, subscription tiers) rather than over a one-time tip to dominance.
Hardware/software systems (consoles, operating systems, smartphones) are the classic indirect network-effect platform: the installed base of users drives complementor (developer) entry, which drives more users. Here the price structure famously subsidizes the hardware (sold near or below cost) and monetizes the software side through royalties, and compatibility decisions—whether to support cross-platform play, common standards, or proprietary lock-in—are the principal competitive lever.
Across all four, the discipline the framework imposes is the same: identify the sides, sign and size the cross-side externalities, read the price structure off the elasticities and externalities, ask whether the market will tip (and whether multihoming will stop it), and recognize that governance is where the value actually accrues.
66.9 Key Takeaways
- A platform’s distinguishing feature is cross-side network effects (Equation 66.1): each side’s value rises with the other’s participation, so demand is interdependent and the firm sells access, not a product.
- The central decision is the price structure, not the price level. The Rochet–Tirole condition (Equation 66.3) says the more elastic side—and the side conferring the larger externality—is subsidized, often below cost or for free; this is an equilibrium, not a promotion.
- Cross-side effects create the chicken-and-egg launch problem: the empty market is always an equilibrium, and platforms escape it by subsidizing a side, going standalone-useful first, or igniting density in a narrow micromarket.
- Network effects create a tendency to tip, but multihoming, differentiation, and congestion determine whether it is realized—“network effects imply winner-take-all” is a half-truth.
- Governance (reputation systems, self-preferencing restraint, openness/control) is where platform value is produced and is what makes an aggressive price structure sustainable.
- Measuring a network effect requires confronting the simultaneity of the two sides; an estimate that ignores it is an upper bound, recoverable only with a valid side-specific instrument, a structural model, or a credible natural experiment.
66.10 Further Reading
The two-sided market was formalized by Rochet and Tirole, with complementary pricing treatments by Parker–Van Alstyne and by Armstrong; the network-effects foundations are due to Katz and Shapiro (1985) and the Katz–Shapiro work on standards. The platform-competition and business-model literature is surveyed in Casadesus-Masanell and Hervas-Drane (2015), and the economics of digital platforms more broadly in Goldfarb, Tucker, and Wang (2022) and Tucker (2019). Multiproduct and bundling considerations relevant to envelopment appear in Armstrong and Vickers (2018). The branding, advertising, and marketing-finance machinery this chapter draws on is developed in Chapter 11, Chapter 13, and Chapter 23.
Akerlof, George A. 1970. “The Market for "Lemons": Quality Uncertainty and the Market Mechanism.” The Quarterly Journal of Economics 84 (3): 488. https://doi.org/10.2307/1879431.
Armstrong, Mark, and John Vickers. 2018. “Multiproduct Pricing Made Simple.” Journal of Political Economy 126 (4): 1444–71.
Berry, Steven, James Levinsohn, and Ariel Pakes. 1995. “Automobile Prices in Market Equilibrium.” Econometrica 63 (4): 841. https://doi.org/10.2307/2171802.
Casadesus-Masanell, Ramon, and Andres Hervas-Drane. 2015. “Competing with Privacy.” Management Science 61 (1): 229–46.
Goldfarb, Avi, Catherine Tucker, and Yanwen Wang. 2022. “Conducting Research in Marketing with Quasi-Experiments.” Journal of Marketing 86 (3): 1–20. https://doi.org/10.1177/00222429221082977.
Katz, Michael L, and Carl Shapiro. 1985. “Network Externalities, Competition, and Compatibility.” The American Economic Review 75 (3): 424–40.
Proserpio, Davide, and Georgios Zervas. 2017. “Online Reputation Management: Estimating the Impact of Management Responses on Consumer Reviews.” Marketing Science 36 (5): 645–65. https://doi.org/10.1287/mksc.2017.1043.
Tucker, Catherine. 2019. “Digital Data, Platforms and the Usual [Antitrust] Suspects: Network Effects, Switching Costs, Essential Facility.” Review of Industrial Organization 54 (4): 683–94.
A further subtlety: indirect network effects mediated by a competitively supplied complement can be re-described as a pecuniary externality rather than a true technological externality. For most marketing purposes the distinction is second order, but it matters for welfare analysis, because pecuniary externalities are transfers and do not by themselves justify intervention.↩︎