flowchart LR A[Intangibility] --> A1[No pre-purchase inspection<br/>→ infer quality from cues] B[Inseparability] --> B1[Production = consumption<br/>→ the service encounter] C[Heterogeneity] --> C1[Performance varies<br/>→ manage the distribution] D[Perishability] --> D1[Capacity cannot be stored<br/>→ match demand to supply] A1 --> Q[Service quality<br/>and satisfaction] B1 --> Q C1 --> Q D1 --> Q
20 Services Marketing
A service is a performance rather than a possession: an act, deed, or performance that one party renders to another, the benefit of which is largely intangible and consumed as it is produced. Where a manufactured good is a noun—a discrete object that can be inventoried, inspected, and returned—a service is a verb, an event that exists only in the interval during which it is delivered. This ontological difference is not a curiosity. It reorganizes the entire marketing problem: there is no shelf to merchandise, no package to design, no unit to recall, and often no way for the customer to evaluate quality until the performance is already underway. The economically dominant share of advanced economies is now organized around exactly these intangible performances, which makes the management of service quality, frontline labor, and customer satisfaction a central rather than a peripheral concern for marketing.
This chapter develops services marketing as a coherent theory rather than a list of tactics. We begin with the four properties—intangibility, inseparability, heterogeneity, perishability—that distinguish services from goods, and show how each property maps onto a specific managerial difficulty and a specific measurement problem. From there we build the central construct of the field, service quality, formalize its leading operationalization (the gaps model and the SERVQUAL instrument), and confront the measurement controversy—difference scores versus perceptions-only—on its own statistical terms. We then connect quality to profit through the service-profit chain, a causal cascade running from internal employee conditions to external customer outcomes to firm value, and we treat the frontline employee as the load-bearing node in that chain. Because services fail in real time and in front of the customer, we give service recovery and the recovery paradox a formal treatment, and we close with satisfaction in services, where the expectation–disconfirmation paradigm supplies both the dominant theory and the dominant national measurement infrastructure.
Throughout, the reader should keep one structural fact in view: in a service, the product and the marketing are frequently the same act, performed by the same employee, in the same moment. That collapse of production and consumption is the source of nearly every difficulty—and every opportunity—the chapter treats.
20.1 What Makes a Service Different
Four properties, conventionally labeled the “IHIP” characteristics, organize the classical account of why services resist the marketing apparatus built for goods. Each is best understood not as a definitional checkbox but as the root of a managerial and a measurement problem.
Intangibility. A service cannot be seen, touched, or stored before purchase. The buyer therefore cannot inspect quality ex ante and must instead infer it from tangible cues—the cleanliness of a waiting room, the credentials on a wall, the demeanor of a receptionist—and from reputation. Intangibility shifts the information problem onto the firm, which must make the invisible legible, and onto the researcher, who cannot measure a physical attribute and must instead measure a perception.
Inseparability. Production and consumption are simultaneous. A haircut is produced at the instant it is consumed; the customer is physically present in the “factory” and frequently co-produces the outcome. Inseparability means quality cannot be inspected out before it reaches the customer, that the customer’s own behavior is an input to the production function, and that the moment of contact between customer and employee—the service encounter—is where value is created or destroyed.
Heterogeneity (variability). Because services are performed by people for people, no two deliveries are identical. The same physician, the same airline, the same call center varies across employees, across customers, and across the same employee on a Monday versus a Friday. Heterogeneity is the enemy of the brand promise: a goods manufacturer can guarantee that every unit is within tolerance, whereas a service firm can only manage the distribution of an inherently stochastic performance.
Perishability. Service capacity cannot be inventoried. An airline seat that flies empty, a hotel room that sleeps no one, an hour of a consultant’s unbilled time—each is lost forever. Perishability turns capacity-and-demand matching (yield management, queuing, appointment systems) into a first-order marketing problem, because the firm cannot smooth demand shocks by drawing down stock.
These properties are ideal-typical, and modern scholarship rightly treats the goods–services boundary as a continuum rather than a dichotomy: most market offerings bundle tangible and intangible elements, and the service-dominant perspective argues that even physical goods are ultimately vehicles for service provision. For the purposes of this chapter we retain the four properties as a diagnostic lens: each tells us where quality is manufactured, where it can fail, and how it must be measured. Figure 20.1 maps each property to the managerial problem it creates.
20.2 Theoretical Foundations
The constructs developed in this chapter do not stand alone; each rests on a governing theory that explains why the phenomenon behaves as it does. Five strands organize the field.
Service-dominant (S-D) logic reframes the goods-versus-services boundary discussed above. Vargo and Lusch argue that value is not embedded in a tangible good and transferred to a passive buyer but is co-created through service exchange, with the customer an active operant resource rather than a destroyer of value (Vargo and Lusch 2004). The later, institutional statement embeds this exchange in service ecosystems coordinated by shared norms and rules (Vargo and Lusch 2016). S-D logic supplies the chapter’s premise that even physical goods are vehicles for service provision and that the service encounter is where value is jointly produced.
The gaps model and SERVQUAL give service quality its dominant operationalization. Parasuraman, Zeithaml, and Berry theorize perceived quality as the customer-facing discrepancy (Gap 5) between expected and perceived service, itself the downstream consequence of four internal provider-side gaps. The account matters because it locates a customer outcome at the end of a chain of managerially actionable organizational deficiencies, which is exactly the structure formalized in Equation 20.2 and Section 20.3.
Justice (equity) theory explains service recovery. Customers evaluate a firm’s response to failure as an exchange judged for fairness, decomposed into distributive, procedural, and interactional justice. This equity lens accounts for the recovery paradox of Section 20.6: a recovery that restores perceived fairness across all three dimensions can lift satisfaction above the no-failure baseline, with the interactional (human, empathetic) component frequently carrying the largest weight.
Role theory accounts for the frontline employee of Section 20.5. The boundary-spanning agent occupies a role defined by two principals (the organization and the customer) whose conflicting expectations generate role conflict and role ambiguity, the structural source of the emotional labor and burnout that degrade delivered quality. Role theory is why the frontline is simultaneously the product and the principal source of quality variance.
Expectation-disconfirmation is the theoretical engine of satisfaction. As formalized in Section 20.7, satisfaction arises from the comparison of perceived performance against a prior expectation, driven principally by the disconfirmation between the two (Oliver and Burke 1999). Its kinship to the SERVQUAL gap is not incidental: both are performance-minus-expectation differences, so both inherit the difference-score liabilities treated in Section 20.3.2.
20.3 Service Quality and the Gaps Model
The central construct of services marketing is perceived service quality: the customer’s global judgment of the superiority or excellence of a service. It is explicitly an attitude—relatively enduring, evaluative, and distinct from the transaction-specific affect of satisfaction (a distinction we sharpen in Section 20.7). The dominant theoretical apparatus, due to Parasuraman, Zeithaml, and Berry, frames quality as the resolution of a chain of internal organizational gaps that culminate in a single external gap between what the customer expected and what the customer perceived they received.
Service quality, as perceived by the customer, is the discrepancy between the customer’s expectations of what a firm should offer and their perceptions of the firm’s actual performance. Quality is high when perceptions meet or exceed expectations and low when they fall short.
The power of the formulation is that it locates a customer-facing outcome (the perception–expectation discrepancy) at the end of a causal chain of internal deficiencies management can act on. The model identifies five gaps, summarized in Table 20.1.
| Gap | Located between | Managerial reading |
|---|---|---|
| 1 | Customer expectations and management’s perception of them | The firm does not know what customers expect |
| 2 | Management perceptions and service quality specifications | The firm knows but cannot codify expectations into standards |
| 3 | Specifications and actual service delivery | Standards exist but the frontline does not meet them |
| 4 | Service delivery and external communications | Promises (advertising, sales) overstate delivery |
| 5 | Expected service and perceived service | The customer-facing gap—a function of Gaps 1–4 |
Formally, write \(E_{ij}\) for customer \(i\)’s expectation on quality attribute \(j\) and \(P_{ij}\) for the same customer’s perception of delivered performance. The customer-facing Gap 5 for attribute \(j\) is
\[ G_{ij}^{(5)} = P_{ij} - E_{ij}, \tag{20.1}\]
and overall perceived quality aggregates the attribute-level gaps, optionally weighting each attribute \(j\) by its importance \(w_{ij}\) (with \(\sum_j w_{ij}=1\)):
\[ \text{SQ}_i = \sum_{j=1}^{J} w_{ij}\,\big(P_{ij} - E_{ij}\big). \tag{20.2}\]
A nonnegative \(G_{ij}^{(5)}\) indicates met-or-exceeded expectations on attribute \(j\); the model’s substantive claim is that this final gap is driven by the provider-side Gaps 1–4, so that management improves perceived quality by closing internal deficiencies rather than by exhorting customers to lower expectations. Figure 20.2 traces this chain from the four provider-side gaps to the customer-facing Gap 5.
flowchart TB
subgraph Customer
EX[Expected service] --> G5{Gap 5}
PS[Perceived service] --> G5
end
subgraph Provider
KN[Mgmt perception of<br/>customer expectations] -->|Gap 2| SP[Quality specifications]
SP -->|Gap 3| DL[Service delivery]
DL --> PS
DL -->|Gap 4| CM[External communications]
CM --> EX
end
EX -.->|Gap 1| KN
20.3.1 The SERVQUAL Instrument
To operationalize Equation 20.2, Parasuraman and colleagues developed SERVQUAL, a multi-item scale that measures expectations and perceptions on a battery of items that load on five dimensions. The five dimensions—reduced from an original ten through factor analysis—are conventionally summarized by the mnemonic RATER:
- Reliability — the ability to perform the promised service dependably and accurately. Empirically the most heavily weighted dimension across most contexts.
- Assurance — the knowledge and courtesy of employees and their ability to convey trust and confidence.
- Tangibles — the appearance of physical facilities, equipment, personnel, and communication materials (the visible proxies for an invisible product).
- Empathy — the caring, individualized attention the firm provides its customers.
- Responsiveness — the willingness to help customers and provide prompt service.
The instrument administers each item twice—once to elicit the expectation (“Excellent firms in this industry will have modern equipment”) and once to elicit the perception (“Firm X has modern equipment”)—on matched seven-point scales, and computes the per-item gap as their difference. Dimension scores average the item gaps within a dimension; the overall score averages across dimensions, weighted or unweighted.
20.3.2 The Difference-Score Controversy
SERVQUAL’s defining design choice—computing quality as the difference \(P-E\)—is also its most contested, and the dispute is genuinely psychometric rather than merely stylistic. The reliability of a difference score is a function of the reliabilities of its components and, crucially, the correlation between them. Let \(P\) and \(E\) have reliabilities \(\rho_{PP}\) and \(\rho_{EE}\), variances \(\sigma_P^2\) and \(\sigma_E^2\), and correlation \(\rho_{PE}\). The reliability of \(D = P - E\) is
\[ \rho_{DD} = \frac{\sigma_P^2\,\rho_{PP} + \sigma_E^2\,\rho_{EE} - 2\,\rho_{PE}\,\sigma_P \sigma_E} {\sigma_P^2 + \sigma_E^2 - 2\,\rho_{PE}\,\sigma_P \sigma_E}. \tag{20.3}\]
The pathology is visible in the algebra: when the components are themselves positively correlated (as \(P\) and \(E\) typically are—customers who expect more of excellent firms also tend to perceive more), the term \(-2\rho_{PE}\sigma_P \sigma_E\) shrinks both numerator and denominator, and the difference score’s reliability falls below that of either component. Difference scores can also suffer spurious correlation with their own components and impose a restrictive constraint—that \(P\) and \(E\) enter the quality judgment with equal and opposite unit weights—that the data need not honor.
These objections motivated the SERVPERF alternative, which discards the expectation battery and measures quality from perceptions alone, \(\text{SQ}_i = \sum_j w_{ij} P_{ij}\). Perceptions-only scores frequently exhibit higher reliability and superior predictive validity for downstream outcomes such as purchase intention, and they halve respondent burden. The defense of the gaps formulation is conceptual rather than statistical: the expectation component carries diagnostic information—telling management not just that quality is low but relative to what standard—that a perceptions-only score discards. The pragmatic resolution adopted in much applied work is to measure perceptions for prediction and to retain expectations for diagnosis, treating the two instruments as serving different jobs rather than competing for the same one. The deeper lesson generalizes beyond services: whenever a construct is defined as a gap, the analyst inherits the difference-score’s measurement liabilities and must justify the equal-and-opposite-weight constraint rather than assume it (cf. the reflective-versus-formative measurement question in Chapter 11).
20.3.3 A Reproducible SERVQUAL Analysis
The following example simulates a SERVQUAL dataset, computes gap scores and dimension means, and contrasts the reliability of the difference score against the perceptions-only score—making the pathology of Equation 20.3 concrete rather than abstract.
Code
set.seed(18)
n_resp <- 400
dims <- c("Reliability", "Assurance", "Tangibles", "Empathy", "Responsiveness")
items_per_dim <- 4
# Latent per-respondent quality propensity and an expectation propensity that is
# positively correlated with it (the source of the difference-score pathology).
quality_latent <- rnorm(n_resp, 0, 1)
expect_latent <- 0.6 * quality_latent + rnorm(n_resp, 0, 0.8)
simulate_block <- function(latent, base, sd_item) {
# 7-point items: clamp a latent-driven Gaussian to [1, 7].
raw <- base + latent + rnorm(length(latent), 0, sd_item)
pmin(pmax(round(raw), 1), 7)
}
# Perceptions average ~5.0; expectations average higher (~6.0): a negative gap.
P <- sapply(seq_len(length(dims) * items_per_dim),
function(k) simulate_block(quality_latent, base = 5.0, sd_item = 0.9))
E <- sapply(seq_len(length(dims) * items_per_dim),
function(k) simulate_block(expect_latent, base = 6.0, sd_item = 0.9))
colnames(P) <- colnames(E) <-
paste0(rep(substr(dims, 1, 3), each = items_per_dim), "_",
rep(seq_len(items_per_dim), times = length(dims)))
# Per-item gap (Eq. for G^(5)) and per-dimension mean gap.
gap <- P - E
dim_index <- rep(dims, each = items_per_dim)
dim_gap <- sapply(dims, function(d) mean(gap[, dim_index == d]))
knitr::kable(
data.frame(Dimension = dims, Mean_Gap = round(dim_gap, 3)),
caption = "Mean SERVQUAL gap (Perception − Expectation) by dimension; negative values indicate unmet expectations."
)| Dimension | Mean_Gap | |
|---|---|---|
| Reliability | Reliability | -0.853 |
| Assurance | Assurance | -0.948 |
| Tangibles | Tangibles | -0.846 |
| Empathy | Empathy | -0.856 |
| Responsiveness | Responsiveness | -0.878 |
Code
# Cronbach's alpha (base R): reliability of a set of items.
cron_alpha <- function(X) {
k <- ncol(X)
total_var <- var(rowSums(X))
item_var <- sum(apply(X, 2, var))
(k / (k - 1)) * (1 - item_var / total_var)
}
alpha_perc <- cron_alpha(P) # perceptions-only (SERVPERF)
alpha_gap <- cron_alpha(gap) # difference scores (SERVQUAL)
cat("Cronbach's alpha, perceptions-only (SERVPERF):", round(alpha_perc, 3), "\n")
#> Cronbach's alpha, perceptions-only (SERVPERF): 0.958
cat("Cronbach's alpha, difference scores (SERVQUAL):", round(alpha_gap, 3), "\n")
#> Cronbach's alpha, difference scores (SERVQUAL): 0.903The perceptions-only scale typically returns the higher reliability, exactly as Equation 20.3 predicts when expectations and perceptions are positively correlated. This is the empirical core of the SERVPERF critique, reproduced from first principles.
20.4 The Service-Profit Chain
Service quality is not pursued for its own sake; the managerial interest is in its consequences for profit. The service-profit chain supplies the causal scaffolding linking the two. In its canonical form it is a cascade: internal service quality drives employee satisfaction; satisfied employees are more loyal and more productive; their loyalty and productivity raise external service value; perceived value drives customer satisfaction; satisfied customers become loyal; and customer loyalty drives revenue growth and profitability.
Profit and growth are stimulated primarily by customer loyalty. Loyalty is a direct result of customer satisfaction. Satisfaction is largely influenced by the value of services provided to customers. Value is created by satisfied, loyal, and productive employees. Employee satisfaction, in turn, results primarily from high-quality internal support and policies that enable employees to deliver results to customers.
The chain is a structural claim, and it is worth writing as one. Let the latent nodes be internal quality \(I\), employee satisfaction \(S^e\), external value \(V\), customer satisfaction \(S^c\), customer loyalty \(L\), and profit \(\pi\). The recursive system is
\[ \begin{aligned} S^e &= \beta_1 I + \varepsilon_1, \\ V &= \beta_2 S^e + \varepsilon_2, \\ S^c &= \beta_3 V + \varepsilon_3, \\ L &= \beta_4 S^c + \varepsilon_4, \\ \pi &= \beta_5 L + \varepsilon_5, \end{aligned} \tag{20.4}\]
so that the total effect of internal service quality on profit is the product of the path coefficients, \(\partial \pi / \partial I = \prod_{k=1}^{5}\beta_k\), under the recursive (no-feedback, uncorrelated-error) assumptions that make this a valid structural decomposition. Two features deserve emphasis. First, the chain is multiplicative: a weak link anywhere collapses the whole, which is why a firm with excellent customer-facing processes but demoralized employees realizes little profit gain. Second, the links are not mechanical identities but estimated empirical relationships, several of which are nonlinear—the satisfaction–loyalty link in particular is famously sigmoid, with loyalty unresponsive in a broad zone of mere satisfaction and rising sharply only at the top of the scale.
The identification challenge is that none of these relationships is delivered causally by cross-sectional correlation. Satisfied customers may be more loyal, or loyal customers may report more satisfaction (reverse causality); a common unobserved cause—say, a customer’s baseline disposition—may inflate every link (omitted-variable bias); and firms that invest in employees may differ systematically in ways the chain does not model (selection). Credible estimates of the chain therefore lean on within-unit variation (employee–customer matched panels, store fixed effects) or on exogenous shocks to one link, and the recursive structure of Equation 20.4 should be read as a maintained modeling assumption, not an established fact. Figure 20.3 lays out the chain link by link, from internal service quality to profit.
flowchart LR I[Internal service<br/>quality] -->|β1| Se[Employee<br/>satisfaction] Se -->|β2| V[External service<br/>value] V -->|β3| Sc[Customer<br/>satisfaction] Sc -->|β4| L[Customer<br/>loyalty] L -->|β5| Pi[Revenue growth<br/>and profit]
The downstream end of the chain—that customer satisfaction and customer equity translate into shareholder value—is now well documented in the marketing–finance literature. Aggregate customer satisfaction, as captured by national indices, is positively associated with firm cash flows, stock returns, and reduced cash-flow volatility, and satisfaction portfolios have been shown to earn abnormal returns (Fornell et al. 2006; Gruca and Rego 2005; Aksoy et al. 2008). Customer satisfaction and customer-based assets thus belong squarely within the marketing-as-investment frame developed in Chapter 23, and the service-profit chain is the micro-mechanism that connects frontline practice to that firm-level payoff.
20.5 Frontline Employees and the Service Encounter
The pivotal node in the service-profit chain is the frontline employee—the person who actually performs the service in the customer’s presence. Because of inseparability, this employee is the product at the moment of contact, and because of heterogeneity, this employee is the principal source of quality variance. The encounter between frontline employee and customer is therefore the “moment of truth” where the firm’s strategy is either realized or undone.
Three structural features make the frontline role distinctive and difficult. First, the frontline employee occupies a boundary-spanning position, standing simultaneously inside the firm and at its edge, and is subject to two principals whose interests routinely conflict: the organization, which presses for efficiency and compliance, and the customer, who presses for responsiveness and accommodation. This conflict is the structural source of emotional labor—the effort of displaying organizationally desired emotions regardless of felt emotion—whose chronic exercise (surface acting in particular) predicts emotional exhaustion and burnout.
Second, the frontline is the locus of internal marketing: the proposition, embedded in the left links of Equation 20.4, that employees are an internal market whose satisfaction, training, and empowerment must be managed as deliberately as the external customer’s. Empowerment—granting frontline staff discretion to resolve problems without escalation—shortens recovery time and raises satisfaction, but it trades off against consistency and cost, so the optimal degree of discretion is an interior solution, not a maximum.
Third, the frontline increasingly works alongside algorithmic and automated systems rather than in isolation. Service is being reorganized around customer self-service technologies, conversational agents, and AI-assisted human agents, which shifts the human role toward the complex, emotional, and exception-handling encounters that automation handles poorly, and raises new questions about how customers respond to non-human service providers and to disclosed automation. Recent frontline scholarship documents how engaged frontline employees and well-designed human–technology configurations propagate through to customer outcomes and firm performance (Harmeling et al. 2016; Umashankar, Bahadir, and Bharadwaj 2021; Neumann, Tucker, and Whitfield 2019; Homburg and Wielgos 2022). The substantive point for this chapter is that automation does not remove the frontline from the service-profit chain; it relocates the human contribution to precisely the encounters—recovery, empathy, ambiguity—where the chain’s coefficients are largest.
20.5.1 Productivity and Quality at the Frontline
A recurring tension in frontline management is the trade-off between productivity (throughput per unit labor) and quality (the perceived excellence of each encounter). Pushing an agent to handle more contacts per hour mechanically reduces the time available per contact, which—beyond a point—degrades perceived empathy and responsiveness. This is also where the operational allocation of customers to service channels becomes strategic: Sun and Shibo (2011) model service- channel allocation (for example, onshore versus offshore routing) as a dynamic programming problem in which the firm learns customer preferences and balances the immediate cost of service against the long-run retention consequences of where and how a customer is served. Their central insight—that myopic cost-minimization in routing can destroy long-horizon customer value—is the frontline analogue of the service-profit chain’s multiplicative structure: squeezing one link for short-run efficiency can collapse the chain’s downstream payoff.
Code
set.seed(181)
# A stylized productivity-quality frontier at the agent level. Quality is a
# concave-decreasing function of throughput (contacts handled per hour); retained
# value per customer rises with quality. The firm chooses throughput to maximize
# total value = throughput * value_per_customer.
throughput <- seq(2, 20, by = 0.5) # contacts per hour
quality <- 100 / (1 + exp(0.35 * (throughput - 10))) # logistic decay in [~0,100]
value_per_customer <- 1 + 0.04 * quality # retained value scales with quality
total_value <- throughput * value_per_customer
opt <- throughput[which.max(total_value)]
plot(throughput, total_value, type = "l", lwd = 2,
xlab = "Throughput (contacts per hour)",
ylab = "Total retained value per agent-hour",
main = "Frontline productivity-quality trade-off")
abline(v = opt, lty = 2, col = "red")
text(opt, max(total_value), labels = paste0("optimum ≈ ", opt), pos = 4, col = "red")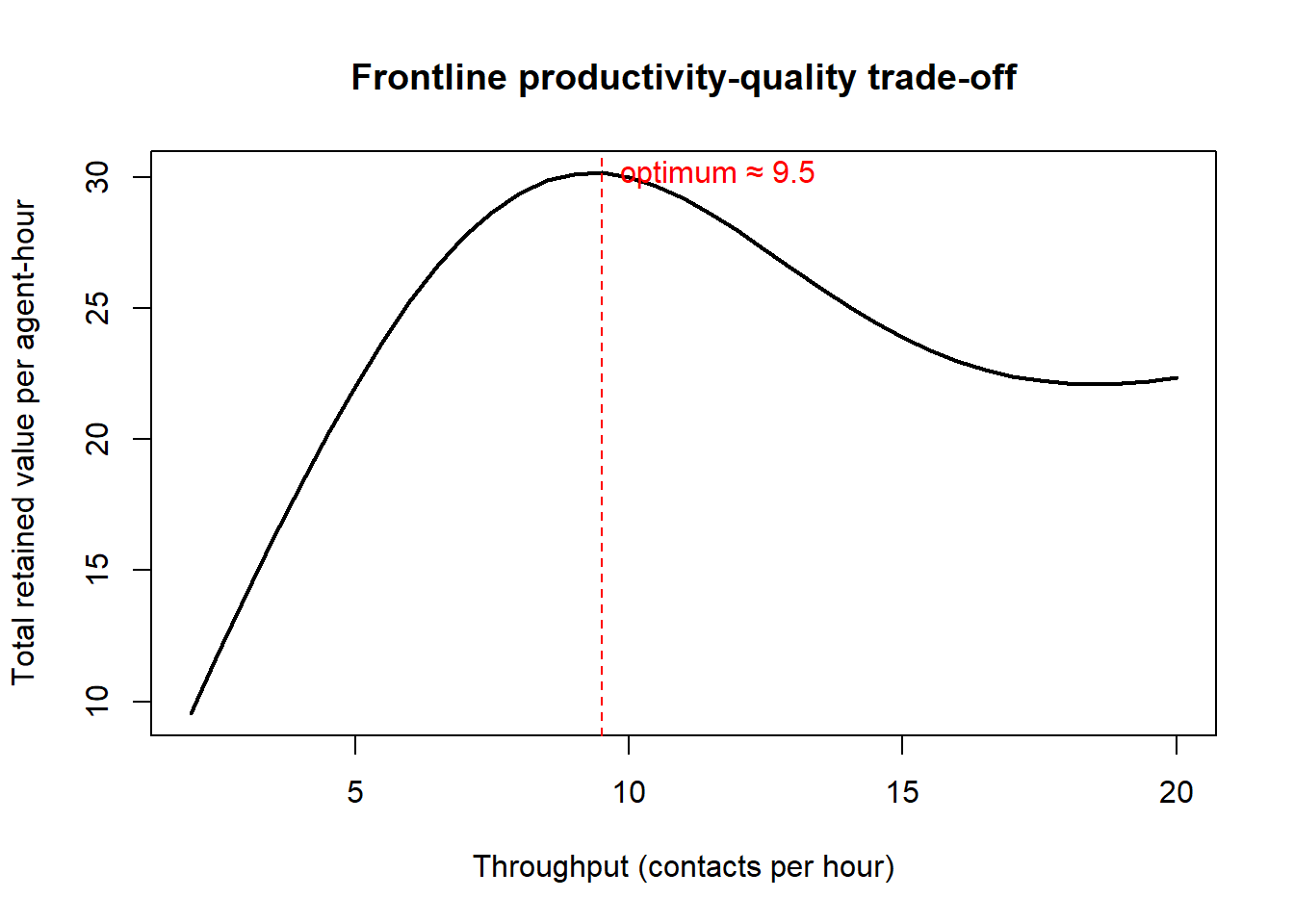
The figure makes the interior optimum explicit: total value is maximized at a moderate throughput, neither at the productivity-maximizing extreme (where quality collapses) nor at the quality-maximizing extreme (where too few customers are served). The exact location of the optimum depends on how steeply quality decays with throughput and how strongly retained value responds to quality—both estimable from matched agent–customer data.
20.6 Service Failure and Recovery
Because services are produced in real time by variable humans, they fail visibly and often. Service recovery is the set of actions a firm takes in response to a service failure, and it is consequential precisely because the failure occurs in front of the customer, with no opportunity to inspect the defect out beforehand. The strategic interest in recovery rests on a striking empirical regularity: a well-handled failure can leave the customer more satisfied and more loyal than if no failure had occurred at all. This is the service recovery paradox.
Let \(S_0\) denote the satisfaction of a customer who experiences flawless service, \(S_f\) the satisfaction of a customer who experiences a failure followed by recovery effort, and \(r \in [0,1]\) the quality of recovery (with \(r=0\) no recovery and \(r=1\) ideal recovery). The recovery paradox is the claim that there exists a threshold \(r^\ast\) such that
\[ S_f(r) > S_0 \quad \text{for } r > r^\ast, \tag{20.5}\]
i.e., sufficiently excellent recovery overshoots the no-failure baseline. The mechanism is twofold. First, a failure converts a routine, low-attention transaction into a diagnostic episode in which the firm’s responsiveness, fairness, and competence are vividly displayed; a strong recovery supplies positive evidence that flawless service never had the chance to provide. Second, customers evaluate recovery through the lens of perceived justice, which decomposes into three components: distributive justice (the tangible outcome—refund, replacement, credit—relative to the harm), procedural justice (the fairness, speed, and convenience of the recovery process), and interactional justice (the courtesy, empathy, and respect with which the customer is treated during the process). Recovery satisfaction rises in all three, and interactional justice—the human, empathetic dimension—frequently carries the largest weight, which again routes the firm’s recovery capability back to the frontline employee of Section 20.5.
The paradox must be stated with two caveats, because managers routinely overread it. First, it is fragile: the meta-analytic evidence indicates the post-recovery satisfaction premium materializes only when recovery is genuinely excellent, when the failure is not severe, and rarely on repeated failures—a customer forgives the first lapse but not the pattern. Second, it is never a strategy: deliberately failing in order to recover spectacularly is dominated by not failing, because recovery is costly, the threshold \(r^\ast\) is high, and severe or repeated failures push the relationship below baseline. The correct reading of Equation 20.5 is defensive—recovery can convert an inevitable failure into a retention opportunity—not offensive.
Code
set.seed(1812)
# Simulate post-episode satisfaction as a function of recovery quality and
# failure severity, illustrating the recovery-paradox threshold.
n <- 1500
recovery_quality <- runif(n, 0, 1) # r in [0,1]
failure_severity <- runif(n, 0, 1) # 0 = minor, 1 = severe
baseline_no_failure <- 7.5 # S_0 on a 10-point scale
# Recovery lifts satisfaction; severity drags it down; interaction: severe
# failures are harder to fully recover from.
satisfaction <- 4.0 +
5.0 * recovery_quality -
3.0 * failure_severity -
2.0 * recovery_quality * failure_severity +
rnorm(n, 0, 0.6)
satisfaction <- pmin(pmax(satisfaction, 0), 10)
paradox <- satisfaction > baseline_no_failure # exceeds the no-failure baseline
# Among MINOR failures, what recovery quality is needed to clear the baseline?
minor <- failure_severity < 0.25
fit <- lm(satisfaction ~ recovery_quality, data = data.frame(satisfaction, recovery_quality)[minor, ])
r_star <- (baseline_no_failure - coef(fit)[1]) / coef(fit)[2]
cat("Share of recovered customers exceeding no-failure baseline:",
round(mean(paradox), 3), "\n")
#> Share of recovered customers exceeding no-failure baseline: 0.051
cat("Approx. recovery threshold r* (minor failures):", round(r_star, 3), "\n")
#> Approx. recovery threshold r* (minor failures): 0.811The simulation reproduces the paradox’s qualitative shape: a sizeable share of minor-failure customers who receive high-quality recovery end up above the no-failure baseline, while severe failures rarely clear it regardless of recovery effort—the empirical content of the caveats above.
20.7 Satisfaction in Services
Customer satisfaction is the post-consumption evaluative judgment concerning a specific transaction or a cumulative relationship. The dominant theory is the expectation–disconfirmation paradigm: satisfaction arises from the comparison of perceived performance against a prior comparison standard (typically expectations), and is driven principally by the disconfirmation between the two (Oliver and Burke 1999; Westbrook 1987). Let \(P\) denote perceived performance and \(E\) the prior expectation. Disconfirmation is
\[ D = P - E, \tag{20.6}\]
with \(D>0\) positive disconfirmation (performance exceeds expectation, raising satisfaction), \(D<0\) negative disconfirmation (lowering it), and \(D=0\) confirmation. A satisfaction model in this tradition regresses satisfaction on expectations, performance, and—most importantly—their disconfirmation:
\[ \text{Sat}_i = \alpha + \gamma_1 E_i + \gamma_2 P_i + \gamma_3 (P_i - E_i) + u_i, \tag{20.7}\]
where \(\gamma_3\) captures the disconfirmation effect over and above the direct (“assimilation”) effect of performance \(\gamma_2\). The paradigm’s relationship to the SERVQUAL gap (Equation 20.1) is now transparent: both are built on a performance-minus-expectation difference, and both inherit the difference-score liabilities of Section 20.3.2—the inclusion of \(E\) and \(P\) as separate regressors alongside their difference in Equation 20.7 is one way to relax the equal-and-opposite-weight constraint that the raw gap imposes.
Two refinements matter. First, satisfaction is distinct from quality: quality is a relatively enduring attitude (a global stance toward the provider), whereas satisfaction is a transaction-specific, more affect-laden judgment; cumulative satisfaction across encounters is one of the inputs that updates the quality attitude over time, not a synonym for it. Second, the satisfaction–loyalty link is asymmetric and nonlinear: dissatisfaction reliably destroys loyalty, but mere satisfaction does not reliably create it—loyalty rises sharply only among the very satisfied (the “delight” region), consistent with the sigmoid link flagged in Section 20.4. This asymmetry is why firms that target a satisfaction mean often fail to move retention: the loyalty payoff lives in the right tail of the distribution, not at its center.
20.7.1 National Satisfaction Indices
The expectation–disconfirmation paradigm is not merely a laboratory model; it is the theoretical engine of national customer-satisfaction measurement. The American Customer Satisfaction Index (ACSI) and its antecedent, the Swedish barometer, operationalize a structural model in which perceived quality and customer expectations drive perceived value and overall satisfaction, which in turn drives complaints and loyalty—essentially the right-hand half of the service-profit chain estimated at the level of the national economy (Fornell 2005; Fornell et al. 2006). The resulting indices are predictive of firm financial performance, and an extensive literature exploits them to show that customer satisfaction is a leading indicator of cash flows and equity returns (Gruca and Rego 2005; Aksoy et al. 2008). These indices matter for two reasons: they supply a continuously updated, comparable measure of service quality across firms and industries, and they convert the soft construct of satisfaction into a hard input for the marketing–finance models of Chapter 23.
Code
set.seed(1816)
# A miniature ACSI-style structural model: expectations and perceived quality
# drive perceived value and satisfaction; satisfaction drives loyalty. We
# simulate from the structural form and recover the path coefficients by OLS.
n <- 1000
expectations <- rnorm(n, 0, 1)
perceived_qual <- 0.5 * expectations + rnorm(n, 0, 0.8)
perceived_value <- 0.3 * expectations + 0.6 * perceived_qual + rnorm(n, 0, 0.7)
satisfaction <- 0.2 * expectations + 0.45 * perceived_qual +
0.40 * perceived_value + rnorm(n, 0, 0.6)
# Nonlinear, asymmetric loyalty: rises sharply only at high satisfaction.
loyalty <- 1 / (1 + exp(-2.0 * (satisfaction - 0.5))) + rnorm(n, 0, 0.1)
dat <- data.frame(expectations, perceived_qual, perceived_value,
satisfaction, loyalty)
m_sat <- lm(satisfaction ~ expectations + perceived_qual + perceived_value, data = dat)
m_loy <- lm(loyalty ~ satisfaction, data = dat)
knitr::kable(
round(summary(m_sat)$coefficients[, c("Estimate", "Std. Error")], 3),
caption = "Recovered satisfaction equation: perceived quality and value are the dominant drivers, consistent with the ACSI structural model."
)| Estimate | Std. Error | |
|---|---|---|
| (Intercept) | -0.003 | 0.019 |
| expectations | 0.224 | 0.024 |
| perceived_qual | 0.416 | 0.028 |
| perceived_value | 0.396 | 0.026 |
The recovered coefficients reproduce the index’s central claim—perceived quality and perceived value, not raw expectations, do the work in predicting satisfaction—while the deliberately nonlinear loyalty equation embeds the asymmetry that makes satisfaction necessary but not sufficient for loyalty.
20.8 Identification and Measurement Pitfalls
Services research is unusually exposed to measurement and identification hazards, and three recur across every construct in this chapter.
Difference-score reliability. Any construct defined as a gap—SERVQUAL quality (Equation 20.1), disconfirmation (Equation 20.6)—inherits the reliability erosion of Equation 20.3 when its components are positively correlated. The remedy is not to abandon the construct but to measure components separately and let the data estimate their weights (Equation 20.7), reserving the raw difference for diagnosis rather than prediction.
Self-selection and survivorship in satisfaction data. Satisfaction surveys are answered disproportionately by the very satisfied and the very dissatisfied, and relationship-level satisfaction is observed only for customers who have not yet defected. Both forces bias naive satisfaction–loyalty estimates: the unhappy middle is underrepresented, and the most dissatisfied have already left the sample. Credible work models the response and retention processes jointly rather than conditioning on survivors.
Reverse causality in the service-profit chain. Every link in Equation 20.4 is vulnerable to simultaneity—loyal customers report more satisfaction; profitable firms can afford happier employees. Cross-sectional correlations among the chain’s nodes are therefore weak evidence for the causal cascade. Identification requires within-unit variation, matched employee–customer panels, or exogenous shocks to a single link, and the recursive, uncorrelated-error structure of the chain should be treated as a maintained assumption to be defended, not a result.
A fourth, subtler hazard is common-method bias: when expectations, perceptions, satisfaction, and loyalty are all collected in a single self-report instrument, their intercorrelations are inflated by shared method variance, which can manufacture an apparent service-profit chain out of measurement artifact. Separating the measurement of antecedents and consequences in time or source is the standard, if costly, defense.
20.9 Key Takeaways
- A service is a performance, and its four classical properties—intangibility, inseparability, heterogeneity, perishability—each map onto a specific managerial and measurement problem (Section 20.1).
- Service quality is a perception–expectation gap (Equation 20.2) located at the end of a chain of internal organizational gaps; SERVQUAL operationalizes it on five RATER dimensions, but its difference-score design erodes reliability when expectations and perceptions correlate (Equation 20.3), motivating the perceptions-only SERVPERF alternative.
- The service-profit chain (Equation 20.4) is a multiplicative recursive cascade from internal employee conditions to firm profit; its links are estimated, often nonlinear, and never delivered causally by cross-sectional correlation.
- The frontline employee is the load-bearing node—simultaneously the product, the principal source of quality variance, and the agent of recovery—and the productivity–quality trade-off has an interior optimum (Section 20.5.1).
- Service recovery can leave customers more satisfied than flawless service (the recovery paradox, Equation 20.5), but the effect is fragile, justice-driven, and never a deliberate strategy.
- Satisfaction follows the expectation–disconfirmation paradigm (Equation 20.6); it is distinct from quality, asymmetrically linked to loyalty, and—aggregated into national indices—a leading indicator of firm financial value (Section 20.7.1, Chapter 23).
20.10 Further Reading
Readers should pair the gaps-model and SERVQUAL primary sources with the difference-score critique to form their own view on the SERVQUAL–SERVPERF dispute, and read the service-profit chain alongside the customer-satisfaction–firm-value literature (Fornell et al. 2006; Gruca and Rego 2005; Aksoy et al. 2008) to see the chain’s downstream end estimated at firm scale. The frontline and service-technology frontier is developing rapidly (Harmeling et al. 2016; Umashankar, Bahadir, and Bharadwaj 2021; Neumann, Tucker, and Whitfield 2019; Homburg and Wielgos 2022), and the dynamic management of service allocation under preference learning is treated in depth by Sun and Shibo (2011). The satisfaction and customer-equity constructs connect forward to the customer-lifetime-value and marketing–finance machinery in Chapter 23.
Aksoy, Lerzan, Bruce Cooil, Christopher Groening, Timothy L. Keiningham, and Atakan Yalçın. 2008. “The Long-Term Stock Market Valuation of Customer Satisfaction.” Journal of Marketing 72 (4): 105–22. https://doi.org/10.1509/jmkg.72.4.105.
Fornell, Claes. 2005. “American Customer Satisfaction Index, 1996.” ICPSR - Interuniversity Consortium for Political; Social Research. https://doi.org/10.3886/ICPSR04208.
Fornell, Claes, Sunil Mithas, Forrest V. Morgeson, and M. S. Krishnan. 2006. “Customer Satisfaction and Stock Prices: High Returns, Low Risk.” Journal of Marketing 70 (1): 3–14. https://doi.org/10.1509/jmkg.2006.70.1.3.
Gruca, Thomas S, and Lopo L Rego. 2005. “Customer Satisfaction, Cash Flow, and Shareholder Value.” Journal of Marketing 69 (3): 115–30.
Harmeling, Colleen M., Jordan W. Moffett, Mark J. Arnold, and Brad D. Carlson. 2016. “Toward a Theory of Customer Engagement Marketing.” Journal of the Academy of Marketing Science 45 (3): 312–35. https://doi.org/10.1007/s11747-016-0509-2.
Homburg, Christian, and Dominik M. Wielgos. 2022. “The Value Relevance of Digital Marketing Capabilities to Firm Performance.” Journal of the Academy of Marketing Science 50 (4): 666–88. https://doi.org/10.1007/s11747-022-00858-7.
Neumann, Nico, Catherine E Tucker, and Timothy Whitfield. 2019. “Frontiers: How Effective Is Third-Party Consumer Profiling? Evidence from Field Studies.” Marketing Science 38 (6): 918–26.
Oliver, Richard L, and Raymond R Burke. 1999. “Expectation Processes in Satisfaction Formation: A Field Study.” Journal of Service Research 1 (3): 196–214.
Sun, Baohong, and Li Shibo. 2011. “Learning and Acting on Customer Information: A Simulation-Based Demonstration on Service Allocations with Offshore Centers.” Journal of Marketing Research 48 (1): 72–86.
Umashankar, Nita, S. Cem Bahadir, and Sundar Bharadwaj. 2021. “Despite Efficiencies, Mergers and Acquisitions Reduce Firm Value by Hurting Customer Satisfaction.” Journal of Marketing, October, 002224292110242. https://doi.org/10.1177/00222429211024255.
Vargo, Stephen L., and Robert F. Lusch. 2004. “Evolving to a New Dominant Logic for Marketing.” Journal of Marketing 68 (1): 1–17. https://doi.org/10.1509/jmkg.68.1.1.24036.
———. 2016. “Institutions and Axioms: An Extension and Update of Service-Dominant Logic.” Journal of the Academy of Marketing Science 44 (1): 5–23. https://doi.org/10.1007/s11747-015-0456-3.
Westbrook, Robert A. 1987. “Product/Consumption-Based Affective Responses and Postpurchase Processes.” Journal of Marketing Research 24 (3): 258. https://doi.org/10.2307/3151636.